
Facebook并没有什么“创造自己语言的失控AI项目”
2022年7月2日作者:破破的桥
本文最早发表于2017-08-03
夭寿啦!人工智能发展出了自己的语言,所有人都看不懂,科学家们担心机器失去控制,迫不得已把项目关掉啦!
实际情况:
1.Facebook的人工智能研究院(FAIR)想训练一个能谈判的聊天程序。通过两个程序之间对抗性地训练和提高,进化出一个比较完善的自动谈判范例。
2.在训练中,因为遗忘了一个英语语法的激励,所以机器在相互谈判时,生成了一些很弱智的错误。这类错误在自然语言处理的研究中司空见惯。用行业黑话说就是“参数没调好,训练飞了”。当研究人员给程序加上英语语法约束后,机器就开始正常交流了。
3.Facebook并没有关闭这个程序,相反,他们发了论文还把代码开源了。
这些新闻是典型的“人工智能威胁人类”论调的材料范本,这些胡扯与臆测建立在无知之上。完整的故事是这样的:
Facebook人工智能研究院(FAIR)想通过两个机器聊天程序对抗的方式,进化出一个谈判力较强的范本。
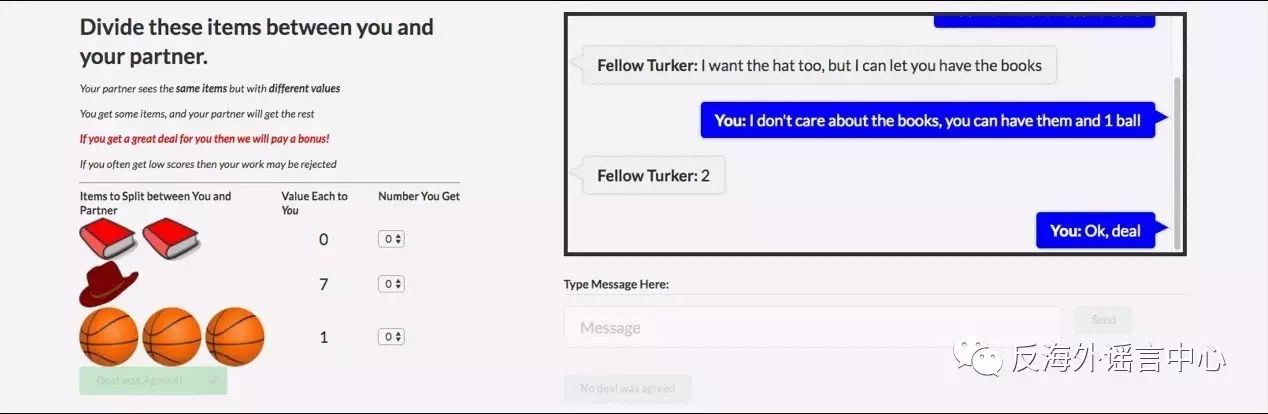
实验是这么设计的,给定一堆物品,比如两本书、一顶帽子、三个篮球。然后放上A(Alice)、B(Bob)两个聊天程序。事先给每个程序设定不同的物品权重,比如说,对A来说,书很重要,每本书的权重是9,帽子和篮球不重要,权重是3。对B来说,篮球很重要,每个篮球的权重是7,帽子和书不重要,权重是4。然后双方在都不知道对方权重数值的情况下,开始相互试探着交换和谈判,试图让自己所获物品的数值之和最大化。谈判一共进行10轮。10轮之内双方达成分配协议,就按各方谈判所得,分别计算分数。如果双方没有达成协议,那么都得0分。
![]()
这个创意中规中矩,但也有些新意:两个程序既需要合作(完成谈判),又需要竞争(在谈判中得到更多利益)。在谈判时,需要回顾之前的对话,推测对方各项物品的权重和谈判策略,然后预判对方之后提出的方案与可能接受的条件。甚至程序还可以伪装自己,表示不看重某件东西,以获得更多的谈判利益。
研究者们使用了约5800条人类真实的谈判句子,作为机器的训练集。并尝试了多个不同的,可在谈判中学习的谈判策略,记录了每个策略最终的得分,写成了论文。这篇论文已经贴在arXiv上[1],程序也已经开源[2]。Facebook发了一篇简要的博客[3]简述了他们的实验方案。
不过,在实验中,研究人员发现了这样的现象。机器在谈判时开始不遵守英语语法:
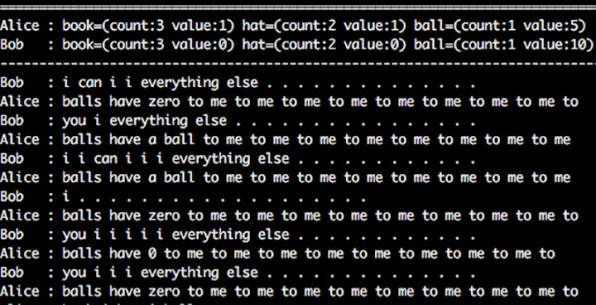
这个谈判对话片段翻译成中文大概是这么个意思:
Bob:我我我我要拿走剩下的一切。
Alice:我只有0个球,球对我非常非常非常非常非常非常非常非常非常非常重要。
这是由于研究人员忘了给机器加上“符合英语语法”的约束激励,所以机器只能采取不停重复某个词汇的方式表达“这东西对我很重要”,显得很“愚蠢”。加上相关约束以后,机器就表现得正常了。
这种语言错乱、不停重复词汇的情况在自然语言处理(比如机器翻译)的研究中经常出现,属于设置错误。而不是什么“失控”。
自然,加上语言系统,也不是因为Facebook的研究人员“对机器发明语言的恐惧”。而是由于这个实验的目标是进一步改进机器与人的交流,不是去提高机器与机器的交流水平。机器之间的正常交流都是用编码,最精准也最快。
目前,神经网络的发展非常迅速,但依然停留在模拟“神经”的程度,只在很有限的几个领域超过了人类,还完全说不上有智能。相反,它们非常愚蠢,一旦有参数错误,就会表现为“神经病”。但把“神经病”的表现包装成“神”来膜拜或恐惧,则是淋漓尽致地表现出人类那种特有的愚蠢了。
参考链接:
[1] https://arxiv.org/pdf/1706.05125.pdf
[2] https://github.com/facebookresearch/end-to-end-negotiator
[3] https://code.facebook.com/posts/1686672014972296/deal-or-no-deal-training-ai-bots-to-negotiate/

